
LocalAI – A Meta bemutatta és letölthetővé tette legújabb AI-innovációját, a Llama 4-et, amely a multimodális intelligencia képességeit fokozó modellek gyűjteménye. A Llama 4 a Mixture-of-Experts (MoE) architektúrán alapul, amely kivételes hatékonyságot és teljesítményt kínál. Ez bennünket nyilván amiatt foglalkoztat, hogy minél erősebb, minél intelligensebb LLM modelleket tudjuk lokálisan (on-prem) futtani, melyek immár egyértelműen felveszik a versenyt az előfizetéses "nagy" publikus AI modellekkel.
Llama 4: Vezető intelligencia.
Páratlan sebesség és hatékonyság. A Llama legkönnyebben elérhető és skálázható generációja megérkezett. Natív multimodalitás, szakértőkből álló keverékmodellek, szuper hosszú kontextusablakok, lépcsőzetes teljesítményváltozások és páratlan hatékonyság. Mindez könnyen telepíthető, az általad kívánt felhasználási módhoz igazodó méretben.
A MoE-modellek és a ritkaság megértése
A Mixture-of-Experts (MoE) modellek jelentősen különböznek a hagyományos sűrű modellektől, ahol a teljes modell minden bemenetet feldolgoz. A MoE-modellekben az összes paraméternek csak egy részhalmaza, az úgynevezett „szakértők” aktiválódnak minden egyes bemenetre. Ez a szelektív aktiválás a bemenet jellemzőitől függ, lehetővé téve a modell számára az erőforrások dinamikus elosztását és a hatékonyság növelését.
A Sparsity (ritkaság) a MoE-modellek alapvető fogalma, amely az inaktív paraméterek arányát jelzi egy adott bemenethez. A MoE-modellek a ritkaság kihasználásával jelentősen csökkenthetik a számítási költségeket, miközben fenntartják vagy növelik a teljesítményt.
Ismerje meg a Llama 4 családot: Maverick és Behemoth.
A Llama 4 család három modellből áll: Llama 4 Scout, Llama 4 Maverick és Llama 4 Behemoth. Mindegyik modellt úgy tervezték, hogy különböző felhasználási eseteket és követelményeket szolgáljon ki.
A Llama 4 Scout egy kompakt modell 17 milliárd aktív paraméterrel és 109 milliárd összes paraméterrel 16 szakértőn keresztül. A hatékonyságra van optimalizálva, és egyetlen NVIDIA H100 GPU-n futhat (FP4 kvantált). A Scout lenyűgöző, 10 millió tokenes kontextusablakkal büszkélkedhet, így ideális a hosszú kontextusmegértést igénylő alkalmazásokhoz.
- Kiváló szöveges- és vizuális intelligencia
- Egyedülálló 10M tokenes kontextusablak
- 17B aktív paraméter x 16 szakértő, 109B összes paraméter
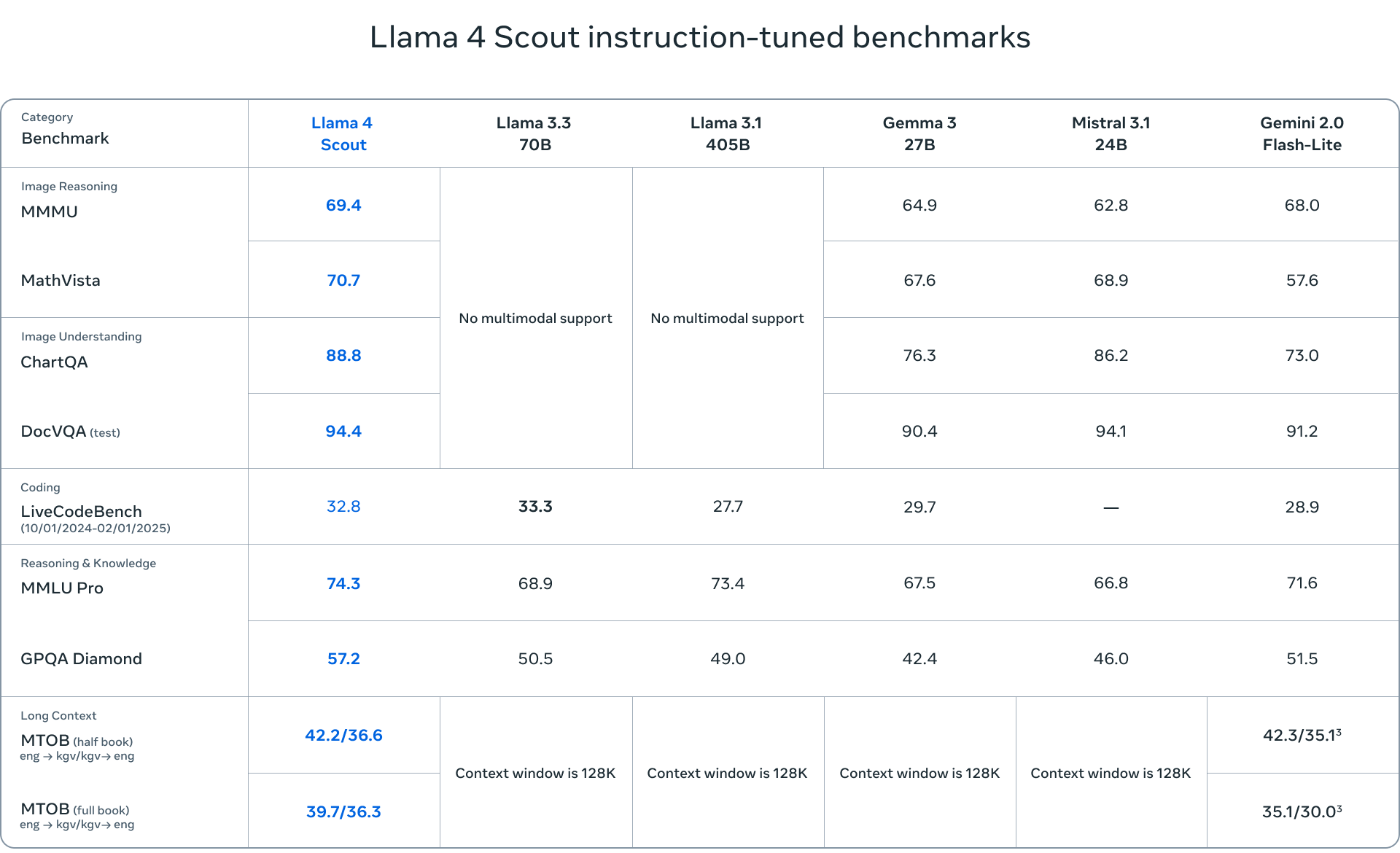
A Llama 4 Maverick egy robusztusabb modell, ugyanolyan 17 milliárd aktív paraméterrel, de 128 szakértővel, összesen 400 milliárd paraméterrel. A Maverick kiválóan teljesít a multimodális megértésben, a többnyelvű feladatokban és a kódolásban, és felülmúlja az olyan versenytársakat, mint a GPT-4o és a Gemini 2.0 Flash.
- A legerősebb nyílt forráskódú (szabadon letölthető) Meta multimodális modell
- Iparági vezető intelligencia és gyors válaszok alacsony költséggel
- 17B aktív paraméter x 128 szakértő, 400B összes paraméter
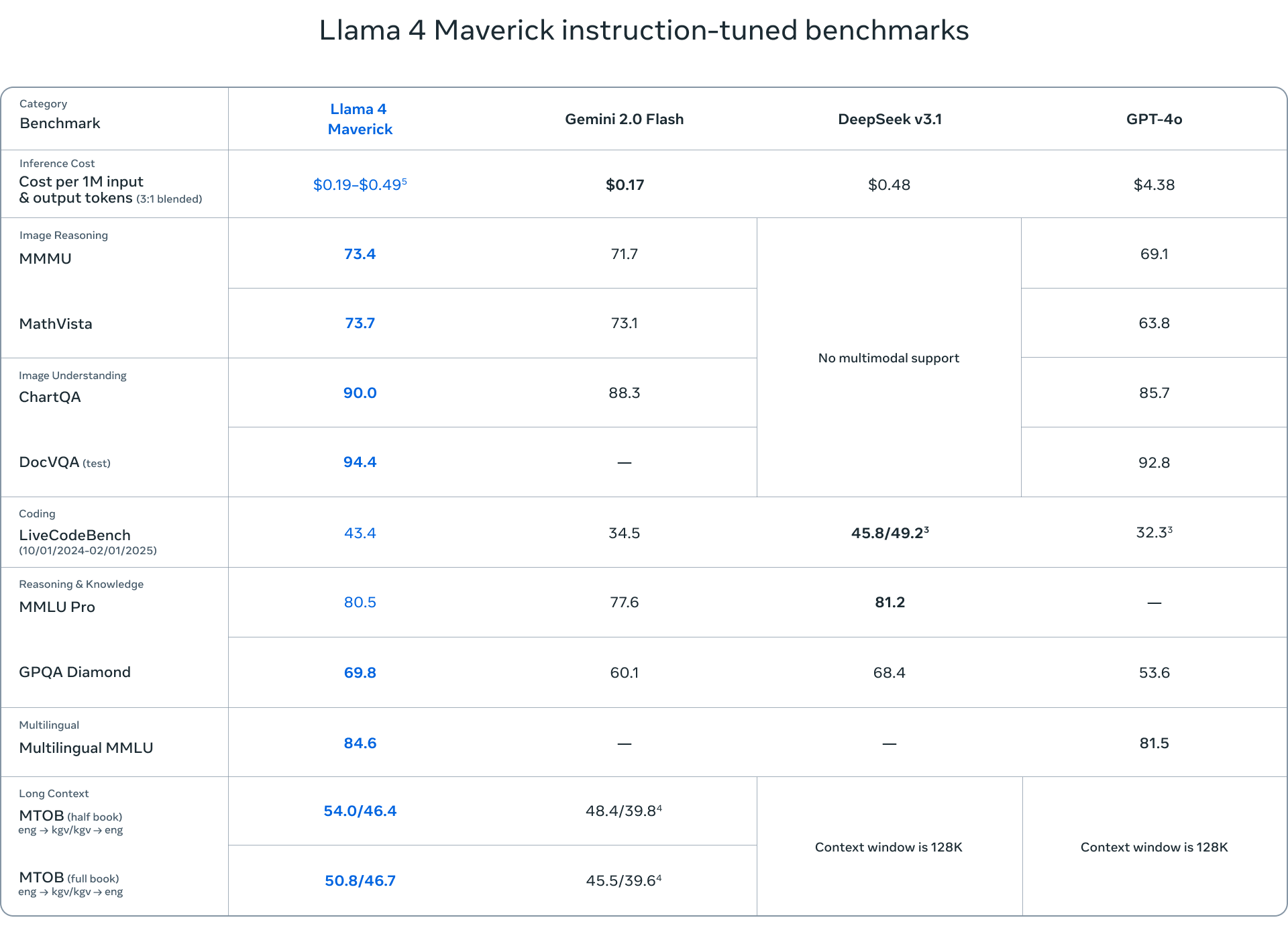
A Llama 4 Behemoth a csomag legnagyobb modellje, 288 milliárd aktív paraméterrel és 16 szakértő összesen közel 2 billió paraméterrel. Bár a Behemoth még mindig a kiképzés alatt áll, máris a legmodernebb teljesítményt nyújtja különböző benchmarkokon, megelőzve olyan modelleket, mint a GPT-4.5 és a Claude Sonnet 3.7.
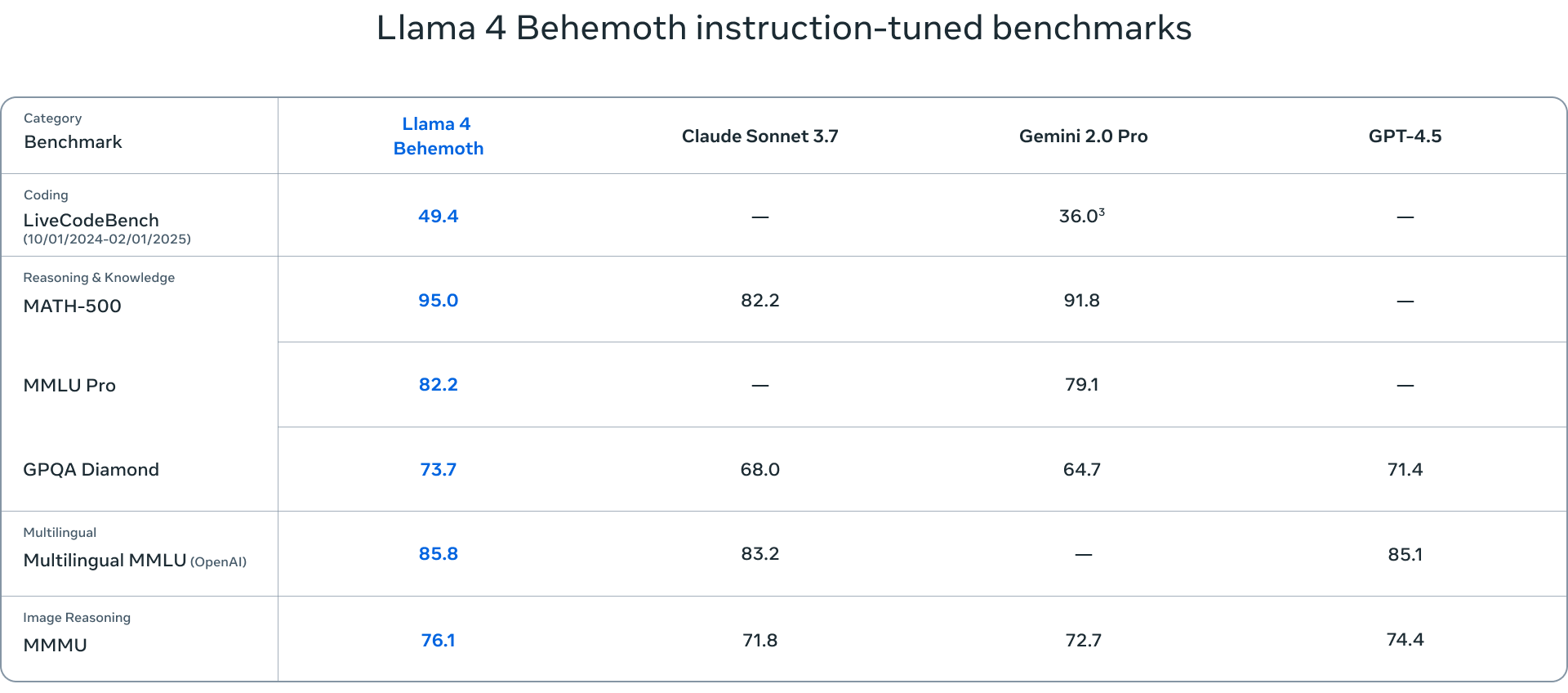
A Llama 4 modellek értékeléséhez használt benchmarkok számos feladatot lefednek, beleértve a nyelvi megértést (MMLU – Massive Multitask Language Understanding, GPQA – Google-Proof Question Answering), a matematikai problémamegoldást (MATH – Mathematical Problem-Solving, MathVista – a vizuális környezetben történő matematikai problémamegoldás benchmarkja) és a multimodális megértést (MMMU – Massive Multimodal Multitask Understanding). Ezek a szabványos benchmarkok átfogó értékelést nyújtanak a modellek képességeiről, és segítenek azonosítani azokat a területeket, ahol kiemelkedőek vagy további fejlesztésre szorulnak.
A tanító modellek szerepe a Llama 4-ben
A tanító modell egy nagy, előre betanított modell, amely irányítja a kisebb modelleket, és desztilláció útján átadja nekik a tudását és képességeit. A Llama 4 esetében a Behemoth a tanító modell szerepét tölti be, és a tudását átadja a Scoutnak és a Mavericknek. A desztillációs folyamat során a kisebb modelleket úgy képzik ki, hogy utánozzák a tanító modell viselkedését, így azok tanulhatnak annak erősségeiből és gyengeségeiből. Ez a megközelítés lehetővé teszi, hogy a kisebb modellek lenyűgöző teljesítményt érjenek el, miközben hatékonyabbak és skálázhatóbbak.
Következmények és jövőbeli irányok
A Llama 4 megjelenése jelentős mérföldkövet jelent a mesterséges intelligencia területén, amely messzemenő hatással van a kutatásra, a fejlesztésre és az alkalmazásokra. A Llama-modellek a múltban katalizátorként működtek a downstream kutatásokhoz, különböző tanulmányokat és innovációkat inspirálva. A Llama 4-es kiadása várhatóan folytatja ezt a tendenciát, lehetővé téve a kutatók számára, hogy a modellekre építsenek és finomhangolják azokat az összetett feladatok és kihívások megoldása érdekében.
Számos modellt finomhangoltak és építettek a Llama-modellekre, demonstrálva a Llama architektúrában rejlő sokoldalúságot és potenciált. A Llama 4 kiadása valószínűleg felgyorsítja ezt a tendenciát, mivel a kutatók és fejlesztők a modelleket új és innovatív alkalmazások létrehozására használják fel. Ez azért jelentős, mert a Llama 4 egy erős modellkiadás, és a kutatási és fejlesztési tevékenységek széles körét teszi majd lehetővé.
Érdemes megjegyezni, hogy a Llama 4 modellek elődeikhez hasonlóan nem gondolkodó modellek. Ezért a Llama 4 sorozat jövőbeli kiadásai potenciálisan utólagosan képezhetők gondolkodásra, ami tovább fokozhatja a teljesítményüket.
AI-szervert keresel?
Speciális munkafolyamatokra szabott AI szervereket és munkaállomásokat építünk akár előtelepített Linux/AI/LLM/RAG környezettel.
Nem tudod, hol kezd? Mi segítünk!
Lépj kapcsolatba AI műszaki tanácsadóink egyikével még ma! Segítünk kiválasztani az adott feladara legalkalmasabb LLM modellt és hozzá a megfelelő hardvert.















