


Videokártya (GPU)
GPU is KING! A legfontosabb láncszem, az LLM-eket használó alkalmazások teljes mértékben a GPU-knak köszönhetően váltak igazán használhatóvá, rendkívüli teljesítményt nyújtanak az ilyen típusú számítási megoldásokhoz.
Milyen típusú GPU (videokártya) kell a nagyméretű nyelvi modellekhez?
A LLM szerver alkalmazásokhoz „Professional” vagy „Compute” szintű GPU-kat ajánlunk. Ez azért van így, mert nagyobb mennyiségű VRAM áll rendelkezésre, és mert jobban alkalmazkodnak a szerverház hűtési környezetéhez.
NVIDIA Ada Lovelace GPU kártyák:
- RTX 6000 Ada Gen (48 GB)
- RTX 5000 Ada Gen (32 GB)
- RTX 4500 Ada Gen (24 GB)
- RTX 4000 Ada Gen (20 GB)
NVIDIA DataCenter GPU-k:
- L40 (48 GB)
- L40S (48 GB)
- A40 (48 GB)
- A100 PCIe (80 GB)
illetve akár az AMD Radeon Instinct PCIe GPU-k.
A kisebb paraméterű LLM-ek viszont remekül futtathatók gamer VGA kártyákon is, egy- vagy két darab RTX 3080/3090, vagy még inkább RTX 4080/4090 videokártyán. Két hátránya van a gamer kártyáknak lokális AI használatra: sokkal nagyobb Wattot vesznek fel és elég komolyan tudnak melegedni, nehezebb megoldani a hatékony hűtést.
Mennyi VRAM (video memória) kell a nagy nyelvi modelleknek?
Az LLM-ekkel való munka során a rendelkezésre álló VRAM teljes mennyisége gyakran a legfőbb korlátozó tényező a megvalósíthatóság szempontjából. Az enterprise szintű telepítések esetében az olyan GPU-k, mint a NVIDIA H200 és H100 páratlan teljesítményt nyújtanak, hatalmas CUDA és Tensor magszámmal, nagy VRAM-mal és rendkívüli memória-sávszélességgel, így ideálisak a legnagyobb modellek (Pl. Llama3 405B) és a legintenzívebb AI-munkaterhelések számára. Ám nincs szüksége mindenkinek arra, hogy a legnagyobb modelleket futtassa a munkájához. Például a Llama 70B paraméteres modell natív, 16 bites (FP16) pontosságú futtatásához körülbelül 80-140 GB VRAM szükséges. A Llama3-70b például jó teljesítménnyel kiszolgálható többfelhasználós környezetben (kis/közepes méretű szervezet) 2x 6000 Ada 48 GB vagy L40s GPU-val. De alacsonyabb kvantálás (precizitás) beállítása mellett kevesebb, vagy kisebb GPU-k (2x RTX 5000 Ada 32 GB, vagy akár 2x RTX 4500 Ada 24 GB) is elegendők lehetnek.
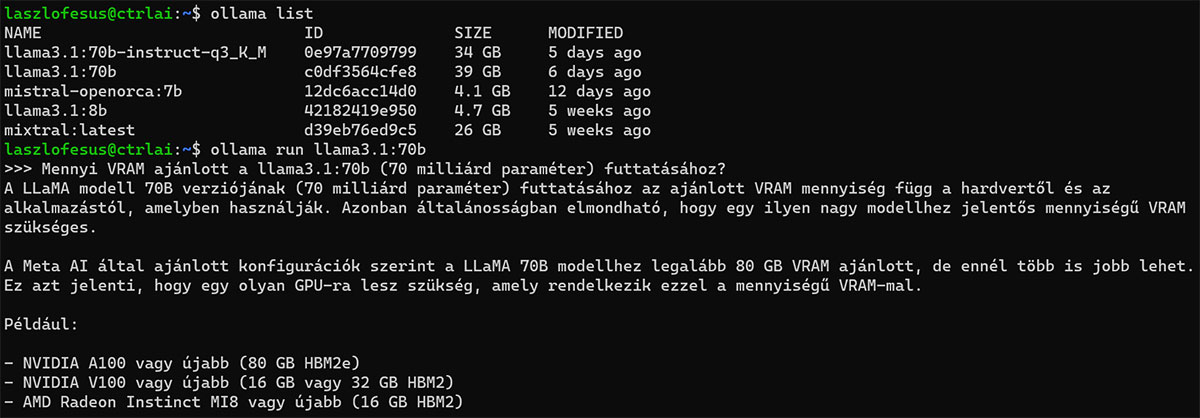
A saját homelab Szerver.Hu CLocalAI Workstation-on megkérdeztem a lokálisan futtatott Llama3.1:70b LLM-et, hogy ő mennyi VRAM-ot javasolna saját magának? Elárulom, ő azért kevesebbet kap, csak 48GB-ot. És köszöni, jól van, szépen fut.
Több GPU javítja az LLM szerverek teljesítményét?
Egyértelműen igen! Az LLM szerverek és keretrendszerek szuperül kihasználják a több GPU-t. Egy Linux-alapú szerver 2-4 GPU-val valójában a „standard” AI rendszer amiket építünk.
A nagy nyelvi modellek jobban futnak NVIDIA vagy AMD GPU-kon?
Az NVIDIA a GPU-számítástechnika történelmi vezetője, és nagymértékben élharcos a mesterséges intelligencia gyors fejlődésében. Továbbra is folytatják az innovációt és generációról generációra jelentős fejlesztéseket hoznak létre a tervezésükben. Az AMD azonban nagyot lépett előre az elmúlt évben. Az AMD ROCm alternatíváját az NVIDIA CUDA mellett aktívan támogatja a Hugging Face és a PyTorch is.
A nagy nyelvi modellekhez „profi” videokártya szükséges?
Technikailag nem, de sokkal nagyobb mennyiségű VRAM-ot kínálnak kártyánként, így komoly LLM szerverekhez szinte mindig ezek a megfelelő választás. Ráadásul a desktop kategóriájú videokártyák általában 3-szlot szélesek, több helyet foglalnak el, kevesebb fér el fizikailag egy szerverben. Mindamellett hűtőrendszerük sem alkalmas rackbe szerelhető házakban való használatra.
És mi újság az AI képgenerálással?
A legnépszerűbb AI- és ML-alkalmazások jelenleg a képgenerálás és -manipuláció körül forognak. Az ilyen típusú hálózatok képzése nagy adathalmazokat igényel, amelyek a képzés során a VRAM-ba íródnak. Könnyebb alkalmazásokhoz kezdetben 12 GB is elegendő, de a komolyabb munkafolyamatokhoz 24 GB VRAM-mal rendelkező RTX 4090-re lesz szükség.
Szükségem van-e NVLinkre, ha több GPU-t használok nagy nyelvi modellekhez?
A legtöbb NVIDIA grafikus kártya már nem támogatja az NVLinket, de vannak olyan kiválasztott GPU-k, amelyek igen, például az NVIDIA H100 NVL. A támogatott GPU-k esetében érdemes az NVLinket használni, de ez nem követelmény az LLM hosztinghoz.
















