
Szóljon ez a cikk az NVIDIA új DGX Spark arany dobozáról, a specifikációkról, a beállításról, a teljesítménymérésekről, az ár/teljesítmény összehasonlításokról más rendszerekkel, és végül egy kis útmutatást adok arról, hogy szerintem kinek lehet a legalkalmasabb ez a fejlesztői doboz.
DIGITS projekt
Az NVIDIA bejelentette a „DIGITS projektet” a 2025. január 5-én Las Vegasban megrendezett CES 2025 kiállításon, azzal az ígérettel, hogy „minden asztalra és minden AI-fejlesztő kezébe kerüljön egy Grace Blackwell chippel felturbózott AI szuperszámítógép.” A hírek szerint ez egy személyes AI szuperkomputer lett volna, amely világszerte AI-kutatók, adatelemzők és diákok számára biztosította volna a NVIDIA Grace Blackwell platform teljesítményét. A DIGITS projekt az új NVIDIA GB10 Grace Blackwell szuperchipet tartalmazta volna, amely petaflopos AI-számítási teljesítményt biztosított volna prototípusok készítéséhez, finomhangoláshoz és nagy AI-modellek futtatásához. Nagyon izgalmasnak tűnt, és alig vártam, hogy többet tudjak meg róla.
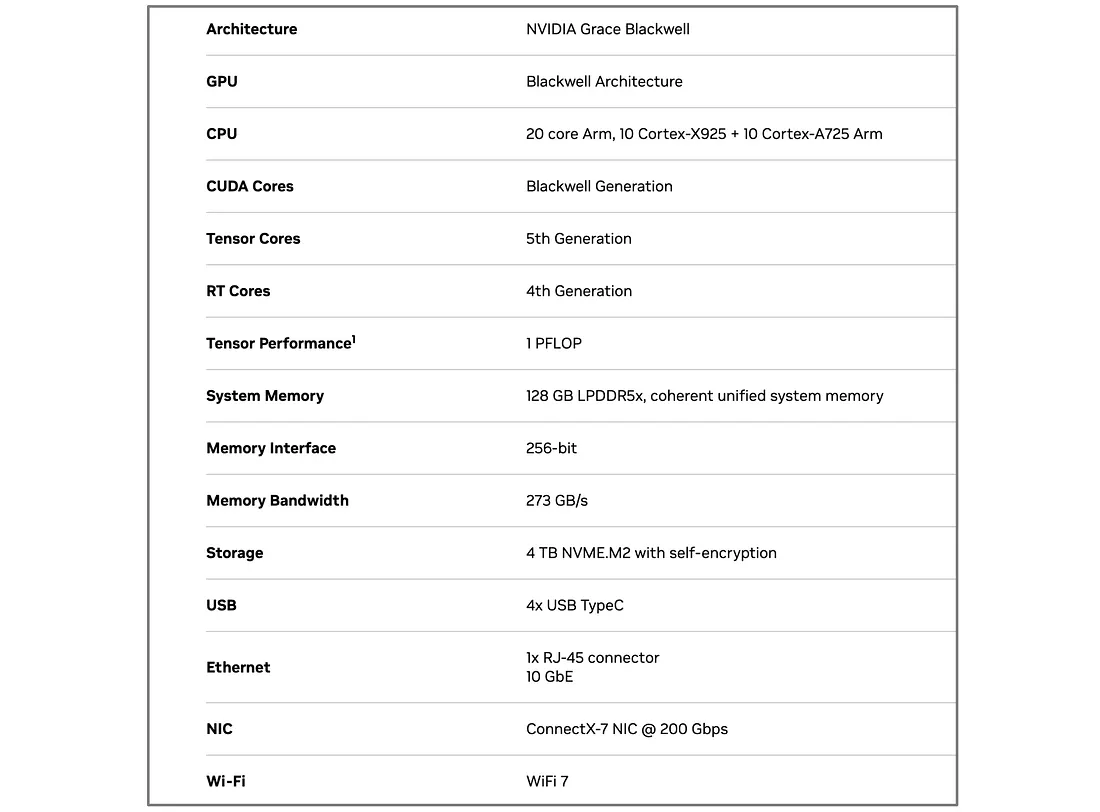

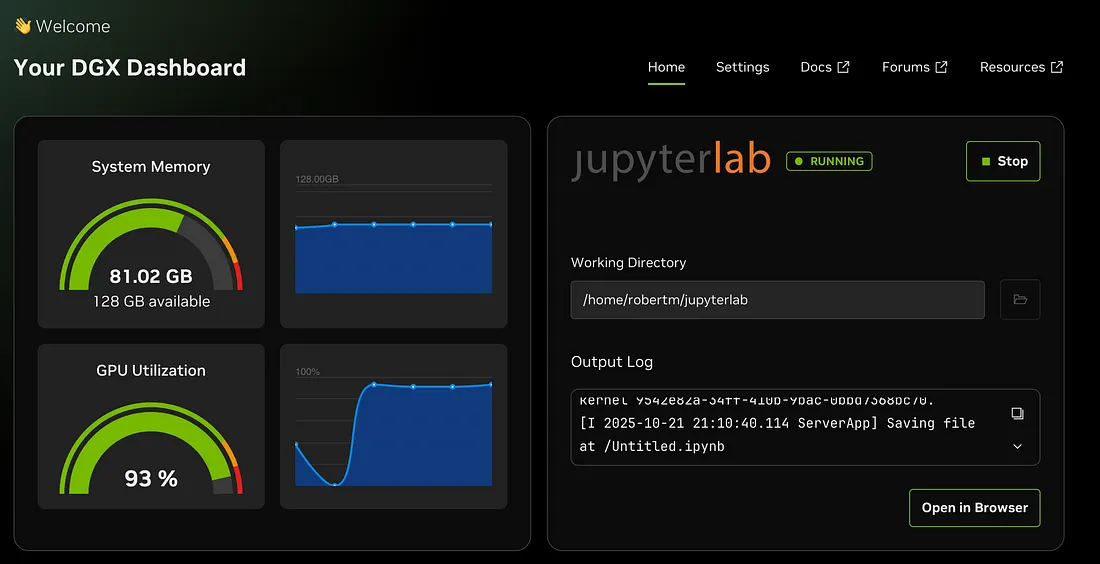
Az NVIDIA közzétette a DGX Spark teljesítménymutatóit különböző feladatokra, többek között finomhangolásra, képalkotásra, következtetésekre (inference) és egyebekre.


















